通信電纜 網(wǎng)絡(luò)設(shè)備 無線通信 云計算|大數(shù)據(jù) 顯示設(shè)備 存儲設(shè)備 網(wǎng)絡(luò)輔助設(shè)備 信號傳輸處理 多媒體設(shè)備 廣播系統(tǒng) 智慧城市管理系統(tǒng) 其它智慧基建產(chǎn)品
成都萬緯信息技術(shù)有限公司

成都萬緯信息技術(shù)有限公司
| 參 考 價 | 面議 |
產(chǎn)品型號
品 牌
廠商性質(zhì)其他
所 在 地成都市
聯(lián)系方式:譚先生查看聯(lián)系方式
更新時間:2024-04-07 12:53:51瀏覽次數(shù):420次
聯(lián)系我時,請告知來自 智慧城市網(wǎng)在DT時代的今天,各行各業(yè)時時刻刻都在產(chǎn)生海量的結(jié)構(gòu)多樣的數(shù)據(jù),企業(yè)數(shù)據(jù)規(guī)模不斷增長,數(shù)據(jù)類型也變得復雜多樣,傳統(tǒng)數(shù)據(jù)庫技術(shù)已無法滿足企業(yè)海量多樣化數(shù)據(jù)的有效存儲、快速讀取以及分析挖掘的需求,急需一套專業(yè)化的大數(shù)據(jù)解決方案來點石成金,H3CDataEngine大數(shù)據(jù)平臺在此背景下應(yīng)運而生
在DT時代的今天,各行各業(yè)時時刻刻都在產(chǎn)生海量的結(jié)構(gòu)多樣的數(shù)據(jù),企業(yè)數(shù)據(jù)規(guī)模不斷增長,數(shù)據(jù)類型也變得復雜多樣,傳統(tǒng)數(shù)據(jù)庫技術(shù)已無法滿足企業(yè)海量多樣化數(shù)據(jù)的有效存儲、快速讀取以及分析挖掘的需求,急需一套專業(yè)化的大數(shù)據(jù)解決方案來點石成金,H3C DataEngine大數(shù)據(jù)平臺在此背景下應(yīng)運而生。
H3C DataEngine 3.0大數(shù)據(jù)平臺基于開源Hadoop3.0而優(yōu)于開源Hadoop,提供一套完整的數(shù)據(jù)實時采集、數(shù)據(jù)存儲、計算、分析、管理與開發(fā)于一體的大數(shù)據(jù)平臺方案。相比開源Hadoop 3.0平臺,DataEngine大數(shù)據(jù)平臺在安全性、易用性、穩(wěn)定性與兼容性等多方面,進行內(nèi)核級優(yōu)化與外圍加固,為用戶提供更貼心、更適合的大數(shù)據(jù)平臺方案。H3C DataEngine大數(shù)據(jù)平臺與H3C CloudOS深度融合,以云操作系統(tǒng)作為基礎(chǔ)底座,形成獨立的數(shù)據(jù)平臺云服務(wù),利用云提供靈活的基礎(chǔ)設(shè)施資源管理,提供海量數(shù)據(jù)存儲以及高性能的查詢分析處理能力,助力企業(yè)用戶快速構(gòu)建海量數(shù)據(jù)處理系統(tǒng),分析挖掘數(shù)據(jù)內(nèi)在價值,并用于指導企業(yè)經(jīng)營決策, 完成業(yè)務(wù)驅(qū)動到數(shù)據(jù)驅(qū)動的轉(zhuǎn)型。
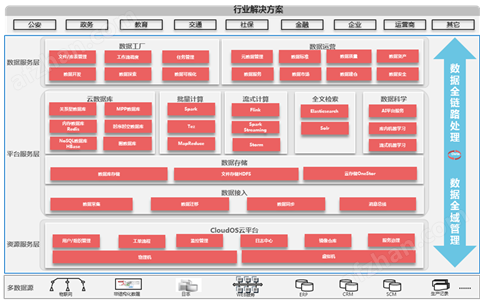
系統(tǒng)架構(gòu)
H3C DataEngine大數(shù)據(jù)平臺,整合基礎(chǔ)資源服務(wù)(IaaS)、平臺服務(wù)(PaaS)、數(shù)據(jù)服務(wù)(DaaS)一站式數(shù)據(jù)解決方案,支持物理機與虛擬機多種資源服務(wù)模式,深度定制大數(shù)據(jù)生態(tài)系統(tǒng),打通數(shù)據(jù)全鏈路開發(fā)處理流程和數(shù)據(jù)全域管理能力,助力企業(yè)業(yè)務(wù)快速創(chuàng)新,完成ICT轉(zhuǎn)型。

數(shù)據(jù)源:大數(shù)據(jù)平臺可對接各種類型的數(shù)據(jù)源,結(jié)構(gòu)化數(shù)據(jù)、非結(jié)構(gòu)化數(shù)據(jù)與半結(jié)構(gòu)化數(shù)據(jù),包括但不限于關(guān)系型數(shù)據(jù)庫、日志、流量、物聯(lián)網(wǎng)數(shù)據(jù)、圖片等。支持接收上一個數(shù)據(jù)處理組件或數(shù)據(jù)接入階段的數(shù)據(jù)。支持自定義的數(shù)據(jù)處理操作,并可向下一個數(shù)據(jù)處理組件發(fā)送數(shù)據(jù);支持多元化數(shù)據(jù)處理方式,包括支持Java、Python、SQL等開發(fā)語言。
資源服務(wù)層:DataEngine大數(shù)據(jù)平臺依托H3C CloudOS云基礎(chǔ)平臺,提供數(shù)據(jù)平臺運行的服務(wù)支撐能力,包括控制臺管理框架、統(tǒng)一用戶組織管理、工單流程管理、組件監(jiān)控告警、日志管理以及微服務(wù)治理、資源池管理等。數(shù)據(jù)平臺服務(wù)支持部署在物理機、裸金屬服務(wù)器和虛擬機,用戶可以根據(jù)實際業(yè)務(wù)場景需求靈活選擇。
平臺服務(wù)層:提供豐富的大數(shù)據(jù)組件即服務(wù),包括但不限于分布式文件系統(tǒng)、NoSQL數(shù)據(jù)庫服務(wù)、內(nèi)存數(shù)據(jù)庫服務(wù)、離線計算、流式計算、內(nèi)存計算等服務(wù),并通過自研統(tǒng)一SQL服務(wù),兼容標準SQL,對外提供統(tǒng)一的數(shù)據(jù)查詢、分析服務(wù),提升平臺的整體易用性。
分布式文件系統(tǒng)支持查詢存儲容量、存儲使用量等信息;支持根據(jù)數(shù)據(jù)價值的高低和存儲周期的長短,定義數(shù)據(jù)的物理存儲節(jié)點,提高集群資料使用效率。根據(jù)數(shù)據(jù)價值高可以存儲配置在SSD盤或者SATA盤的節(jié)點上,同時提供gzip、或lzc、或snappy、或其它存儲壓縮算法。
數(shù)據(jù)服務(wù)層:在數(shù)據(jù)存儲與計算平臺服務(wù)之上,還提供數(shù)據(jù)工廠、數(shù)據(jù)開發(fā)、數(shù)據(jù)資產(chǎn)以及數(shù)據(jù)質(zhì)量等增值服務(wù),形成統(tǒng)一數(shù)據(jù)標準規(guī)范,真正形成數(shù)據(jù)資產(chǎn)化,滿足上層應(yīng)用的數(shù)據(jù)要求。
H3C DataEngine 大數(shù)據(jù)平臺產(chǎn)品包括以下關(guān)鍵特性:
多數(shù)據(jù)源的快速采集:數(shù)據(jù)集成服務(wù)通過簡易的工作流管理界面,可輕松將存儲在文件、關(guān)系型數(shù)據(jù)庫、實時數(shù)據(jù)流(如設(shè)備syslog信息)等各類數(shù)據(jù)源中的海量結(jié)構(gòu)化數(shù)據(jù)、非結(jié)構(gòu)化數(shù)據(jù)、半結(jié)構(gòu)化數(shù)據(jù)采集至大數(shù)據(jù)集群中。
海量數(shù)據(jù)的存儲:對結(jié)構(gòu)化、半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)提供低成本存儲,通過的Ensure Code技術(shù)實現(xiàn)數(shù)據(jù)低冗余、高容錯,并通過集群高可用和多副本機制,避免單節(jié)點故障,保證節(jié)點損壞時數(shù)據(jù)不丟失。此外平臺還具有高可擴展性,用戶可以增加集群節(jié)點數(shù)量,橫向擴展數(shù)據(jù)存儲和計算能力。
支持對集群內(nèi)服務(wù)器硬盤故障自動容錯處理,支持硬盤熱插拔,故障硬盤的業(yè)務(wù)恢復時間< 2分鐘。
元數(shù)據(jù)庫支持快速切換容災(zāi),故障時可在1分鐘內(nèi)完成服務(wù)恢復。
多計算框架融合:融合了穩(wěn)定的離線計算MapReduce、高效的內(nèi)存計算Spark以及實時的流計算Flink等多種計算框架,為客戶提供靈活的計算支持能力,全面支持各類計算業(yè)務(wù)場景,客戶無需切換平臺或架構(gòu)即可完成復雜多變的計算任務(wù)。在各類計算框架之上H3C DataEngine通過自研的統(tǒng)一SQL引擎,高度兼容標準SQL,智能選擇計算引擎,極大降低使用復雜度,為上層應(yīng)用程序提供標準的JDBC/ODBC/REST接口、多種語言的編程API和DaaS接口,輔以BI展示和可視化工具,通過即時報表、直方圖、柱狀圖等方式直觀呈現(xiàn)數(shù)據(jù)價值。
可視化數(shù)據(jù)工廠:提供一站式數(shù)據(jù)接入、可視化的數(shù)據(jù)開發(fā),全托管的數(shù)據(jù)處理流程調(diào)度,實現(xiàn)一整套全生命周期數(shù)據(jù)開發(fā)服務(wù),適用于數(shù)據(jù)建倉、數(shù)據(jù)分析與探索、業(yè)務(wù)報表生成、實時數(shù)據(jù)預警等業(yè)務(wù)場景。
豐富的行業(yè)應(yīng)用: H3C DataEngine大數(shù)據(jù)平臺經(jīng)過不斷的產(chǎn)品優(yōu)化和架構(gòu)演進,已經(jīng)成功在、醫(yī)療、電力、稅務(wù)、高校等多個行業(yè)落地實施,配合行業(yè)的應(yīng)用服務(wù)開發(fā)商為客戶提供豐富的大數(shù)據(jù)應(yīng)用。
容災(zāi)備份:可對關(guān)鍵組件元數(shù)據(jù)、文件、表進行備份和恢復;數(shù)據(jù)備份和數(shù)據(jù)恢復,支持全量或增量備份。數(shù)據(jù)中心間的數(shù)據(jù)集群備份,滿足多中心之間的數(shù)據(jù)互備需求,備份過程可視化管理。
多租戶支持:通過對物理或虛擬資源的分配實現(xiàn)多個租戶以及他們的計算和數(shù)據(jù)彼此隔離和不可訪問。
隔離管理:支持多租戶并行執(zhí)行,租戶任務(wù)提交到不同的隊列執(zhí)行,租戶間資源隔離。
權(quán)限管理:支持各業(yè)務(wù)組件的租戶統(tǒng)一管理,實現(xiàn)租戶資源的動態(tài)配置和管理,資源隔離,資源使用統(tǒng)計等功能,支持多級租戶的管理功能。
調(diào)度管理:支持多集群和多資源池的多租戶調(diào)度。





| 服務(wù)名稱 | 版本號 | 描述 |
|---|---|---|
| YARN | 3.0.0 | Hadoop資源管理器,是一個通用的資源管理系統(tǒng),可為上層應(yīng)用提供統(tǒng)一的資源管理和調(diào)度服務(wù),使MapReduce、Spark、Flink等多種計算框架共享資源 |
| HDFS | 3.0.0 | Hadoop分布式文件系統(tǒng),具有高容錯、高吞吐等特點,適用于存儲超大文件 |
| MapReduce2 | 3.0.0 | 批處理框架,主要用于離線計算、計算密集型應(yīng)用。設(shè)計思想是分而治之,即將一個大任務(wù)分成多個獨立的小任務(wù),最后匯總各個小任務(wù)的結(jié)果 |
| ZooKeeper | 3.4.5 | 分布式應(yīng)用程序協(xié)調(diào)服務(wù),為集群提供一致性服務(wù),包括配置維護、名字服務(wù)、分布式同步、組成員管理等 |
| Spark | 2.4.0 | 一個快速的通用的大規(guī)模數(shù)據(jù)處理引擎,提供批處理、流處理、SQL查詢、機器學習、圖計算、R語言等功能。Spark計算中的中間結(jié)果緩存在內(nèi)存中,在后續(xù)計算過程中直接讀取緩存數(shù)據(jù),具有高效的計算性能。 |
| Storm | 1.2.1 | Storm是一個分布式的、容錯的實時流處理引擎,效率非常高且能保證每條消息都能被處理 |
| Tez | 0.9.0 | 一個支持DAG作業(yè)的計算框架。Tez將多個有依賴關(guān)系的作業(yè)轉(zhuǎn)化為一個DAG作業(yè),大幅提升性能,幫助MapReduce克服在迭代計算和交互式計算方面的不足 |
| HBase | 2.1.1 | HBase是一個分布式、面向列的NOSQL數(shù)據(jù)庫,常用于非結(jié)構(gòu)化和半結(jié)構(gòu)化數(shù)據(jù)的存儲和查詢。在應(yīng)用程序開發(fā)中,常使用Java API等接口訪問HBase中的數(shù)據(jù),也可以借助Phoenix等SQL引擎使用JDBC訪問HBase中的數(shù)據(jù) |
| Redis | 5.0.4 | Redis是Key-Value型內(nèi)存數(shù)據(jù)庫,支持單機和集群兩種運行模式,常用作高速緩存和消息隊列代理 |
| Flink | 1.6.0 | Flink是一個批處理和流處理結(jié)合的統(tǒng)一計算框架,其核心是一個提供了數(shù)據(jù)分發(fā)以及并行化計算的流數(shù)據(jù)處理引擎 |
| ElasticSearch5 | 7.4.0 | ElasticSearch是一個基于Lucene的全文搜索服務(wù)器,提供了一個分布式的、多用戶全文搜索引擎。對外提供RESTful編程接口,特點是易擴展、實時搜索、穩(wěn)定可靠,是當前流行的企業(yè)級搜索引擎 |
| Solr | 7.4.0 | Solr是一個基于Apache Lucene項目的搜索平臺。其主要功能包括全文搜索、命中突出、面搜索、動態(tài)集群、數(shù)據(jù)庫集成和豐富的文檔(如Word、PDF)處理 |
| Hive | 2.1.1 | 基于Hadoop的數(shù)據(jù)倉庫工具,可以將結(jié)構(gòu)化的數(shù)據(jù)文件映射為一張數(shù)據(jù)庫表,并提供簡單的類SQL查詢功能,具有以下特點: · 易于進行數(shù)據(jù)抽取、轉(zhuǎn)換和加載 · 支持多樣的數(shù)據(jù)存儲格式 · 能直接訪問存儲在HDFS或其他的數(shù)據(jù)存儲系統(tǒng)(如HBase)上的文件。多種使用方式,支持Shell交互式命令、JDBC、WebUI等 |
| Impala | 3.2.0 | Impala是用于處理存儲在Hadoop集群中的大量數(shù)據(jù)的MPP(大規(guī)模并行處理)SQL查詢引擎,提供了高性能和低延遲查詢分析能力。 |
| Kafka | 2.3.0 | 一種高吞吐量的分布式發(fā)布訂閱消息系統(tǒng) |
| Infra Solr | 0.1.0 | Infra Solr是一個專門提供給LogSearch服務(wù)的企業(yè)級搜索應(yīng)用服務(wù)器 |
| Sqoop | 1.4.7 | Sqoop是一個用于Hadoop和結(jié)構(gòu)化數(shù)據(jù)存儲(如關(guān)系型數(shù)據(jù)庫)之間進行高效傳輸大批量數(shù)據(jù)的工具: · Hadoop數(shù)據(jù):HDFS文件、HBase表、Hive表 · 關(guān)系型數(shù)據(jù)庫:MySQL、PostgreSQL、Oracle、SQL Server和DB2等支持JDBC的數(shù)據(jù)庫 |
| Kerberos | 1.10.3.10 | Kerberos是一種不依賴主機地址信任、不要求網(wǎng)絡(luò)中所有主機的安全,通過密鑰系統(tǒng)為客戶機和服務(wù)器應(yīng)用程序提供強大的認證服務(wù)的網(wǎng)絡(luò)認證協(xié)議 在Hadoop中,使用Kerberos來安全訪問各個服務(wù) |
| HBase Indexer | 1.5 | HBase Indexer是針對HBase開發(fā)的索引插件,使HBase支持二級索引 |
| Oozie | 5.1.0 | Oozie是用于Hadoop平臺的工作流調(diào)度引擎,管理Hadoop作業(yè) |
| Flume | 1.9.0 | Flume是一個分布式的、高可靠的、高可用的將大批量的不同數(shù)據(jù)源的日志數(shù)據(jù)收集、聚合、移動到HDFS進行存儲的系統(tǒng) |

您感興趣的產(chǎn)品PRODUCTS YOU ARE INTERESTED IN







智慧城市網(wǎng) 設(shè)計制作,未經(jīng)允許翻錄必究 .? ? ?
請輸入賬號
請輸入密碼
請輸驗證碼



